基于以太坊的排序和原生执行
@eomjipark 关于 “基于以太坊的排序和原生执行(based sequencing and native execution)” 的讲解非常透彻而且易懂,忍不住将 其在 X 上的讲解 翻译成中文在此留存。以下是整个线程的译文:
1/
最近大家都在谈论基于以太坊的排序和原生执行,但它们到底是什么?
在参加了 @drakefjustin 举办的一场关于原生 Rollup 的精彩研讨会后(参考资料将在文末列出),我想借此机会用简单的语言分享我最近的学习心得,特别是针对那些对这个话题感兴趣但还不太熟悉的人。
让我们通过以太坊这台世界计算机提供的服务视角,来深入了解不同 L2 的思维模型。🤿
2/
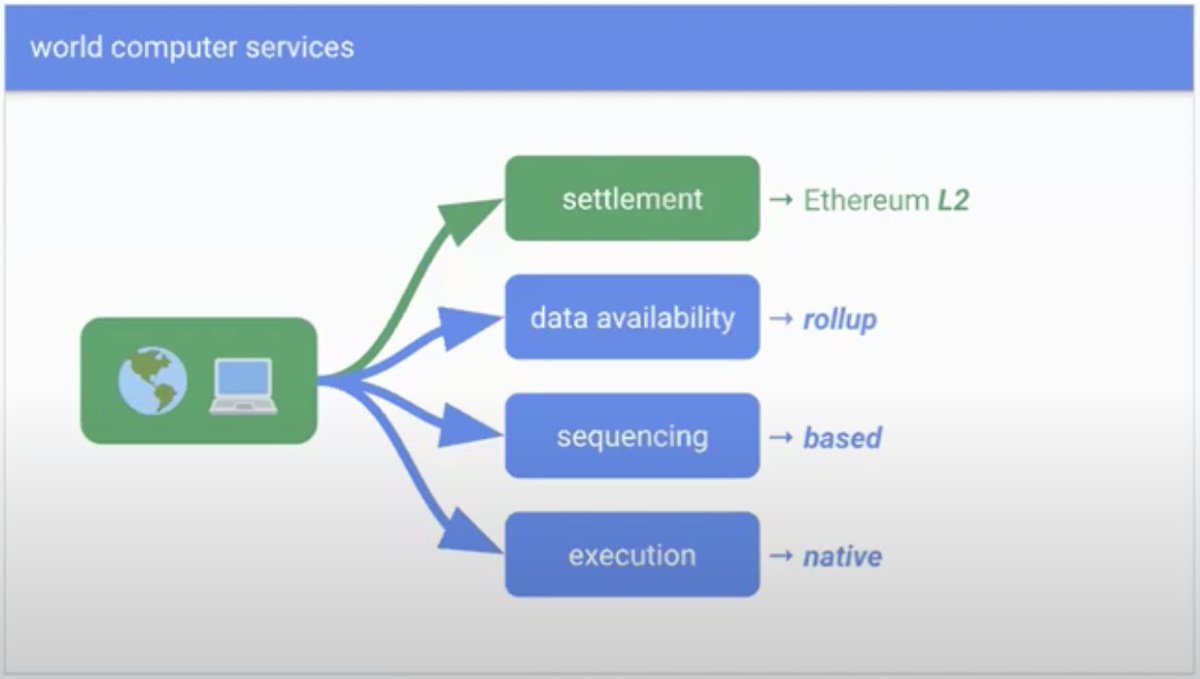
以太坊作为世界计算机提供多种服务:结算、数据可用性(DA)、排序和执行。你使用这些服务的组合方式决定了你在生态系统中的独特定位。
3/
结算是将 L2 的最终状态安全地锚定到以太坊的过程。
通过将状态根(系统状态的紧凑摘要)发布到以太坊账本,L2 可以利用以太坊强大的信任和安全保障,这些保障由数十亿美元的质押 ETH 和去中心化共识支持。
这确保了即使 rollup 遇到问题,最终状态仍然可以在以太坊上保持安全并可恢复。
4/
数据可用性(DA) 确保验证 L2 状态所需的所有信息都可以在链上访问。如果你的 L2 依赖以太坊的数据来重新计算其状态,它就符合 rollup 的定义。简单来说,DA 保证了验证 rollup 状态所需的原始数据(如交易历史)被安全存储且可透明访问。
当 rollup 直接在以太坊(L1)上存储其交易数据时,任何人都可以独立验证状态转换,而无需依赖外部方。
然而,在以太坊上存储数据成本很高,这导致许多 L2 采用替代性的 DA 解决方案,如 @eigen_da(被 @megaeth_labs 使用)和 @Celestia(被 @EclipseFND 使用),这些方案提供链下数据可用性,同时保持透明性和可验证性。
5/
排序决定了 L2 内部交易的处理顺序。在去中心化系统中,交易顺序至关重要,因为它会影响最终状态并影响费用和交易执行。
大多数 L2 使用自己的排序器,这是一个专门的系统,用于收集交易、对其排序,并将打包后的结果提交给以太坊。虽然这种方法提供了灵活性,但也引入了中心化和操作复杂性。(目前,大多数 L2 都运行中心化的排序器。)
然而,基于以太坊的 Rollup 依赖以太坊的验证者(或提议者)来对交易进行排序,消除了对专用排序器的需求。这减少了运营开销,并确保交易排序是去中心化和无需信任的。
6/
关于基于以太坊的排序/Rollup 的一些有趣观点 🤔
-
L2 目前通过向用户收取交易排序费用来产生收入。使用 L1 排序后,L1 和 L2 之间可能会出现收入分享机制,这引发了关于如何分配利润的问题。另一方面,如果排序完全去中心化,L2 应该分享其收入。
-
像 @EspressoSys、@AstriaOrg 和 @radius_xyz 这样的共享排序器网络旨在去中心化交易排序。然而,如果以太坊的排序被广泛采用,它们的价值主张可能需要演变。除了以太坊之外,它们还能提供什么额外的好处?成本竞争力是否会成为它们的主要优势?
7/
执行指的是运行处理交易、更新状态和生成结果所需的计算。在以太坊上,这由 EVM(以太坊虚拟机)处理,EVM 是世界计算机的”大脑”。
对于大多数 L2 来说,执行是在链下进行的,或通过自定义虚拟机完成。然而,原生 Rollup 更进一步,直接利用以太坊的执行层(EVM)来处理交易,使 rollup 成为以太坊的原生组件。
通过依赖以太坊的执行层,原生 Rollup 消除了对定制解决方案(如自定义错误证明系统、电路或安全委员会)的需求。
这简化了兼容 EVM 的 rollup 的部署,并使它们与以太坊的原生架构紧密对齐。
8/
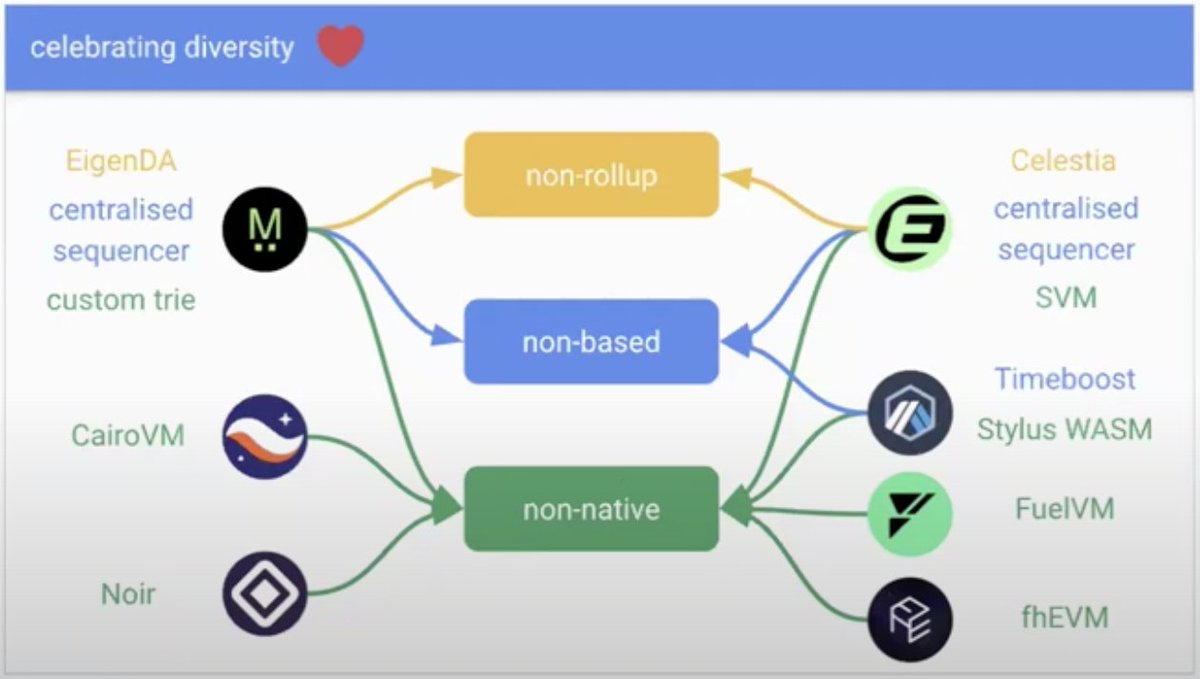
并非所有 rollup 都会走向原生化,有些会因其独特优势而保持非原生设计。
- @megaeth_labs 使用自定义 trie 来实现更快的状态更新和更高的交易吞吐量。
- @arbitrum WASM 支持 WebAssembly (WASM),使得更广泛的开发者群体能够参与,而不仅限于熟悉 Solidity 和 EVM 的开发者。
- @aztecnetwork Noir 通过自定义零知识编程模型优先考虑隐私保护计算,独立于以太坊的原生执行。
- @Starknet Cairo VM 为基于 Stark 的 rollup 提供动力,通过其独特的虚拟机实现可扩展性和计算效率。
还有很多!这些多样化的虚拟机突显了针对特定用例、开发者需求和性能目标的各种设计选择,推动着以太坊生态系统内外的创新。
9/
重要的问题是,现有的 L2 将如何应对这种范式转变?1月17日,主要的 L2 技术栈参与者进行了一次同步会议,讨论合作事宜。
总的来说,所有与会者都对这一倡议表示强烈支持。虽然这可能有些偏差,因为参会者可能本就支持这项工作,但看到主要参与者分享想法并表示支持仍然令人鼓舞。
特别引人共鸣的是 @ben_chain @Optimism 的一句话(意译):“如果我们想要获胜,我们必须改进并共同努力实现它。这是战时状态。”
参考资料已包含在文末,强烈建议进一步学习。
10/
以下是一些关键要点和个人思考。
-
扩展挑战:尽管有人抱怨采用速度慢,但增长是稳定的,我们仍未为大规模采用做好准备。像 @Optimism 和 @base 这样的团队指出,按目前的发展速度,即使在 Proto-Danksharding 中引入 blob 存储后,数据使用瓶颈很快就会变得关键,这突显了扩展工作的紧迫性。
-
多样性与碎片化:生态系统的设计选择多样性对实验很有好处,但造成了碎片化,使互操作性和协调变得具有挑战性。虽然保持设计灵活性很重要,但共享标准将加快进展。建设者仍可以探索独特的方法,同时受益于基线对齐。
-
L1、L2 和其他参与者之间的收入分享:L1 和 L2 之间的收入分享问题仍然至关重要。例如,@Unichain(一个 DEX)计划成为原生的但不基于以太坊,因为其创新在于从优化交易排序和管理 MEV 中提取价值。
11/
-
法律和安全优势:基于以太坊的和原生 rollup 可以通过消除对专门安全委员会的需求来提供合法保护,这对我来说是一个有趣的观点/学习。
-
标准和协调:以太坊基金会正在与相对中立的合作伙伴合作制定标准和协调。我之所以加上”相对”,是因为中立性总是主观的,因为竞争优先级和设计理念自然会影响合作。
-
工具和框架开发:几个团队正在开发工具和框架来支持这些新范式。值得注意的是,@spire_labs 正在修改 OP Stack 以支持基于以太坊的排序。像 @NethermindEth、@OpenZeppelin、@taikoxyz 和 @puffer_finance 这样的团队正在测试/构建部署模板,旨在简化基于以太坊的和/或原生 L2 的开发。
12/
总之,原生 Rollup 通过直接利用以太坊的执行层,架起了以太坊和 rollup 之间的桥梁,使执行变得无缝和安全。这一进步为 EVM RollAPPs(应用特定的 rollup)铺平了道路,这些 rollup 易于部署,使开发者能够专注于构建创新应用,而不是管理基础设施。
虽然由于过去的技术限制,所有 rollup 目前都是非原生的,但变革已经开始。主要的 L2 技术栈参与者正在支持像 @Commit_Boost 提出的 FABRIC 框架这样的倡议,推动这一演进向前发展。
13/
以太坊正在大步前进,生态系统合作伙伴共同努力巩固其地位。@dankrad 呼吁以太坊要更有雄心壮志,这与社区的共同愿景产生共鸣:要么雄心勃勃,要么放弃。
(当然,Dankrad 没说要放弃…)
激动人心的时刻就在眼前。期待看到这一切的到来!
14/
以下是帮助我理解原生 Rollup 和相关内容的各种演讲和文章。
- 📺 原生 Rollup 研讨会:https://youtu.be/03TMJo6ByRs
- 📜 基于以太坊的 Rollup 研究文章:https://ethresear.ch/t/based-rollups-superpowers-from-l1-sequencing/15016
- 📜 原生 Rollup 研究文章:https://ethresear.ch/t/native-rollups-superpowers-from-l1-execution/21517
- 📺 以太坊排序和预确认 #17:https://youtu.be/IekfClKumx8
- 🧵 Ben Fish 的 X 帖子:https://x.com/benafisch/status/1882956031480999972
- 🧵 Dankrad “我们需要有雄心”:https://x.com/dankrad/status/1881405119373234238